IMDb Sentiment Analysis

Overview
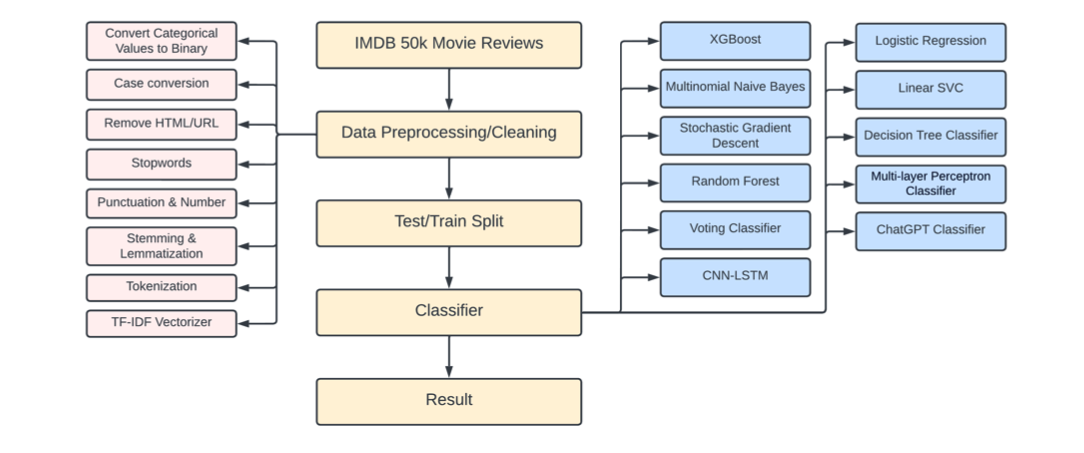
This work tackles binary sentiment (positive vs negative) on the public IMDb review benchmark (50k reviews). The pipeline runs from raw text cleanup through TF-IDF features for classical models up to a CNN-LSTM hybrid that reaches about 90% accuracy in the reported experiments. In total, eleven model families were trained and compared side by side so the lift from traditional ML to deep sequence modeling is easy to see.
Everything needed to reproduce figures and metrics lives in the open imdb-sentiment-analysis repository on GitHub, including notebooks and PDF write-ups.
Deliverables
- A reproducible preprocessing and baseline notebook (Main.ipynb): cleaning, normalization, TF-IDF features, and classical model runs.
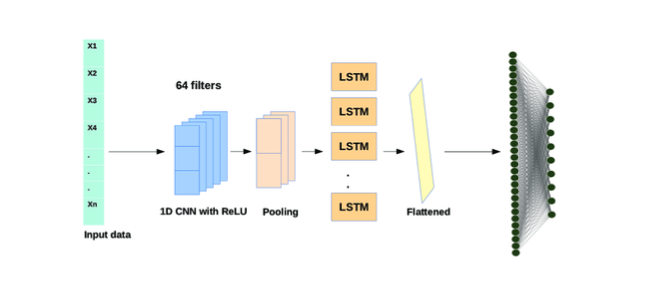
- A dedicated CNN-LSTM notebook (CNN_LSTM.ipynb) for the hybrid architecture and training configuration that peaks near 90% accuracy.
- A formal written report (PDF) covering methods, comparisons, and results.
- A slide-style presentation (PDF) summarizing the project for a quick read.
Technology stack
- Language: Python in Jupyter Notebook.
- NLP foundations: text cleaning, stemming/lemmatization, tokenization, TF-IDF vectorization.
- Classical ML: models such as logistic regression and random forest on sparse TF-IDF inputs (alongside other baselines in the eleven-model sweep).
- Deep learning: CNN-LSTM hybrid for sequence-friendly sentiment classification.
Preprocessing and features
Reviews were stripped of HTML noise, URLs, stopwords, and punctuation where appropriate, then normalized with stemming and lemmatization before tokenization. TF-IDF builds the sparse feature matrix for traditional learners; the deep model path consumes sequences suited to convolution plus LSTM stacking.
Modeling and results
The eleven-model study spans lightweight linear and ensemble methods through the CNN-LSTM design. The hybrid pairs convolutional layers for local n-gram patterns with LSTM recurrence for longer-range order in the review text. In the documented runs it lands near 90% accuracy, ahead of the classical baselines in the same benchmark setup.
Natural next steps (not implemented here) would include transformer-style encoders or ensembles, as noted in the repository README.