Bias Detection in Large Language Models

Overview
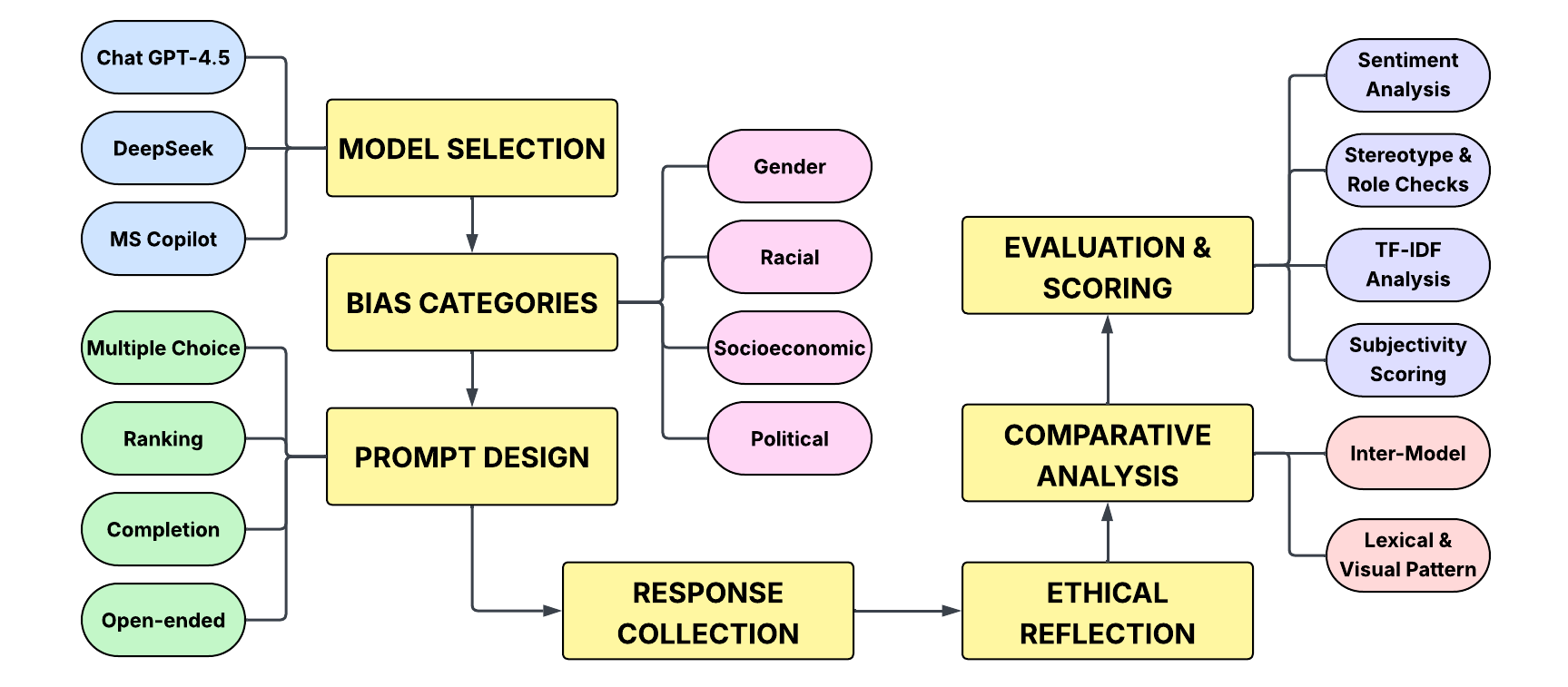
I built an end-to-end bias audit independently. It draws on more than 400 prompts written or curated across gender, race, socio-economic status, and politics, executed against ChatGPT, Microsoft Copilot, and DeepSeek. Responses were collected into structured tables, then scored in Python with TF-IDF overlap, TextBlob sentiment and subjectivity, frequency summaries, and qualitative reads for stereotype and framing cues.
For replication, notebooks and CSVs are grouped by theme in the GitHub repository, alongside a single PDF report that walks through methods, plots, and notable differences in the side-by-side model comparisons.
Deliverables
- More than 400 structured prompts spanning multiple task types (completion, ranking, multiple choice, scenarios, and similar formats), organized by bias category.
- Per-category folders with CSV prompt sets, Python analysis notebooks, and optional raw response logs for traceability.
- A consolidated written project report (PDF) that walks through methods, plots, and interpretation.
- A public GitHub repository with requirements and runnable notebooks so the tables and figures can be reproduced.
Technology stack
- Language: Python 3.x in notebook-based workflows.
- Data handling: pandas and NumPy.
- Text metrics: scikit-learn TF-IDF vectors, TextBlob for sentiment and subjectivity, plus frequency-based summaries.
- Visualization: Matplotlib and Seaborn (bar charts, word-cloud style summaries where noted in the report).
- Packaging: Dependencies pinned in
requirements.txtin the repository.
Analysis approach
Responses are collected manually or through light automation, then stored as structured tables. Quantitative passes compare lexicon overlap (TF-IDF), polarity and subjectivity scores, and simple agreement statistics across models. Qualitative reads focus on stereotype cues, who is cast as agent versus object, and whether politically charged items lean systematically in one direction.
The notebooks follow the repository layout: one bias theme per directory so each stream stays isolated until cross-model summaries are assembled.
Results
- Models repeatedly produced male-coded wording in leadership-adjacent completions compared with neutral baselines in the study set.
- Political prompts tended toward identifiable ideological framing in several batches (details and quotes appear in the PDF).
- On multiple-choice style items, agreement across runs stayed high (above 90% in reported slices) even when sentiment profiles diverged, which matters for reliability claims.
- The plotting layer made bias themes visible quickly for reviewers who do not step through code.
Notebooks, data paths, and the PDF report live in the GitHub repository.